.png)


Are you wondering what the different Power BI storage modes are? Which one is right for you? Whether DirectQuery and LiveConnection are the same thing? Maybe you've heard of something called DirectLake that claims to solve all your problems and are thinking, really? Well, if you need answers to any of these questions or anything related to Power BI storage modes, read on!
Let's Start With The Basics!
So, what exactly are Power BI storage modes? I used to call them connectivity types, but it seems Microsoft isn't using that term as much anymore, so storage modes it is. Storage modes are the methods available for establishing a connection and interacting with the underlying source.
May 2025 Update: Live Connect is technically a connectivity type, not a storage mode. However, for simplicity, I’ve grouped all the options under “Storage Modes” in this blog to make the comparison easier to follow. As mentioned above, I’ve traditionally referred to them as connectivity types - but having a single view of all these options is helpful for readers.
So, a Storage Mode is basically a Data Connector, Got it!
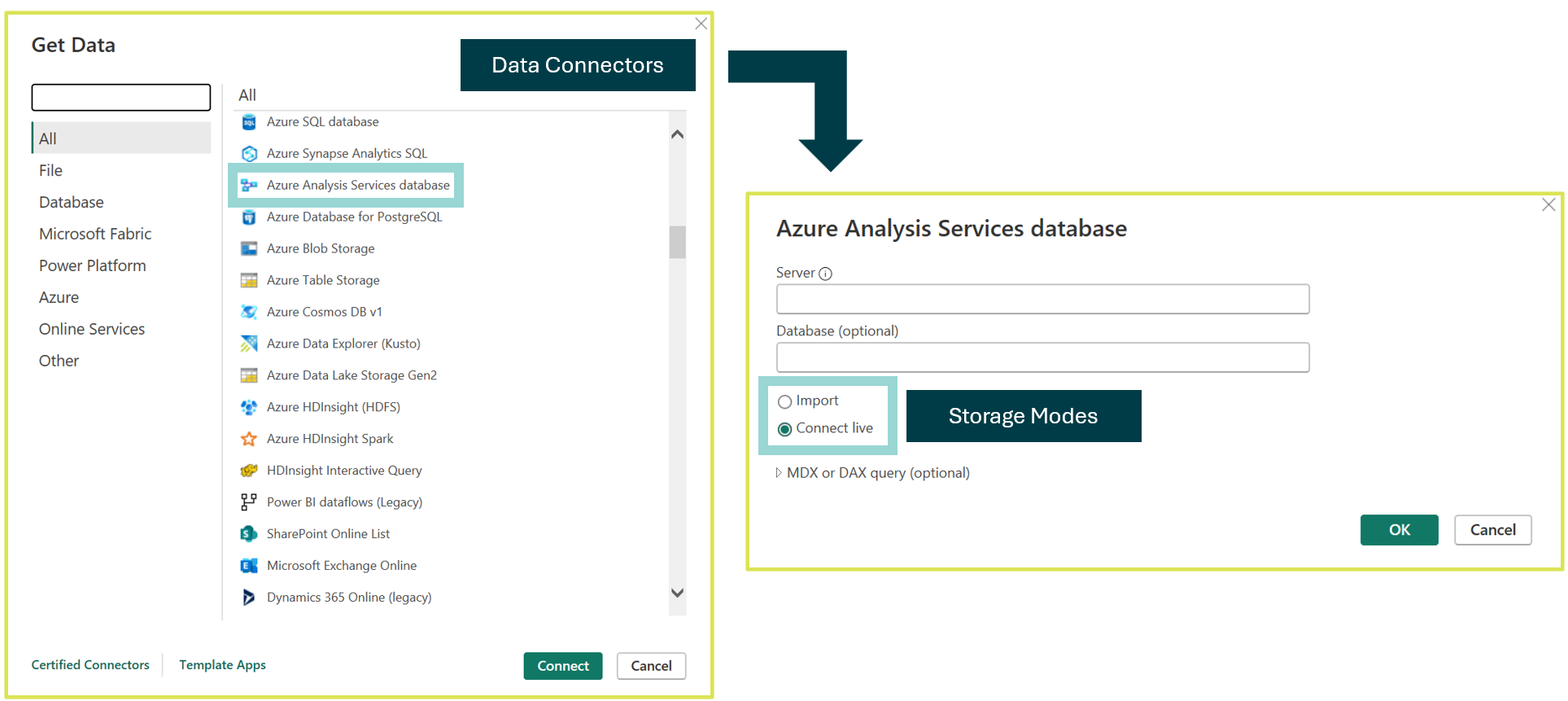
Nooo! Storage modes and data connectors in Power BI are two different things. Data Connectors are simply the data sources that we can ingest or pull data from. Check out the helpful diagram below to see the distinction.
A single data connector can offer multiple storage modes. For example, when connecting to "Azure Analysis Services database", we can choose between Import or a LiveConnection storage mode.
To put this into context, when we first launch Power BI Desktop, we are presented with a blank canvas - no data, measures, visuals and nothing pretty! 😲 To start, we must select "Get Data", which displays all the available DATA CONNECTORS. After choosing a data connector from the list, as shown in the diagram below, we can select from the available STORAGE MODES. However, if the data source only supports one storage mode, such as Excel, you won’t see options for choosing a storage mode.
Storage Mode Breakdown
There are five storage modes that can be used when interacting with a data source, each offering unique benefits and limitations. The storage mode you choose can also influence the overall usage and capabilities available within Power BI Desktop. This makes it crucial to select the most appropriate mode for your purpose from the outset.

Import
We start with the Import storage mode, the most common storage mode used in Power BI and the default selection when connecting to most data sources. First thing to know, when using Import mode, all data ingested is stored in the Power BI model, therefore the PBIX file and hosted in memory. Storing and reading data directly from memory boosts performance in accessing and retrieving data, making Import the fastest of all storage modes. Isn't DirectLake the fastest? Don't worry, we'll cover that shortly. All of this is made possible by the engine behind Power BI (and Analysis Services), called VertiPaq (also known as xVelocity). It's an in-memory columnar database that compresses and stores all data efficiently.
Since the data is stored within the Power BI model when using Import, any queries triggered by users interacting with report visuals are directed to the Power BI semanticmodel, not the original data source The underlying data source is only queried by Power BI during the refresh process when using Import. This means the PowerBI model must be scheduled for refresh to ensure the reports have the most up-to-date information.
Earlier, I mentioned that certain storage modes come with limitations. However, Import offers the full capabilities of Power BI Desktop, allowing you to transform data from multiple sources, build models, and leverage all reporting and DAX functions without restrictions. Also, with all the great performance benefits Import brings, we should always keep our memory usage in mind as there are limitations in regard to how large our Power BI semantic model can be. With Pro licensing, the Power BI model cannot exceed 1GB after compression, however with Power BI Premium (Fabric Capacity) this can reach levels of 400GB using the Large Model option.
DirectQuery
We now move toDirectQuery where the important element to understand is that no data isingested and stored in the Power BI semantic model. This is the reverse of howthe Import works, as Import stores all the data within the PBIX file and keepsit in memory. While the actual data isn’t stored in Power BI, the metadata is -such as table names, relationships, field names, and more. By not storing datain the Power BI model, you can handle larger volumes without hitting thelimitations like the 1GB cap in Pro licensing. DirectQuery, which is primarilyavailable for relational database sources, helps avoid these restrictions.
When using DirectQuery, any interactions with the reports will generate queries that are sent to the underlying data source to retrieve information, which is then displayed in the visuals. The advantage here is that the data stays on the source side, providing near real-time access without the need for scheduled refreshes. However, this can affect both the reporting experience for users and the performance of the underlying data source, especially when too many users are generating queries simultaneously. Here is a quick tip, Query Reduction options exist in Power BI Desktop to reduce the number of queries generated and sent to source.
It's important to know, DirectQuery does have some limitations on Power BI Desktop's capabilities. For example, some DAX functions are unavailable as they can add too much complexity to queries sent to the underlying data source. Also, certain Power Query transformations, are also restricted. Additionally, DirectQuery can only retrieve up to 1 million rows from the data source. For full list of limitation, click this link here.
LiveConnection
I’m calling this out now because, even today, I still see people, even Power BI experts, using DirectQuery and LiveConnection interchangeably, like they’re the same thing. They are very different! These to storage modes are usually mixed up because they both don’t store data in the Power BI model. With that said, using a LiveConnection means no data is stored in the Power BI model, therefore all interaction with a report using a LiveConnection will directly query the existing Analysis Services model.
LiveConnection can be used with SQL Server Analysis Services (don't find this much anymore), AzureAnalysis Services, and Power BI semantic models. It’s important to note that these sources are analytical engines, so the overall performance is much higher compared to DirectQuery. Additionally, these sources provide a semantic layer that acts as a single version of the truth, delivering a "golden layer" of high-integrity, well-governed data. That’s why I refer LiveConnection to the enterprise choice. Drop a comment if you disagree with this, especially with DirectLake now being available.
As always, some restrictions do exist. However, since all the work is done in the Power BI semantic model or Analysis Services, we're leveraging an existing enterprise-level model. It makes sense that there are limitations on data transformation and modelling capabilities. Also, there are some limitations on DAX measures you can create when using LiveConnection - only report-level measures are available. This means the measures are stored in your Power BI report and aren't written back to the semantic model. The good news is, all reporting capabilities in Power BI are still fully available when you're using a LiveConnection.
Mixed
We have arrived to Mixed mode, also referred to as composite models. In simple terms, what is this? It allows us to take the above storage modes we went through and combine them. However, we need to be aware of a few things before using this storage mode.
Let’s say I start with Import mode, which makes sense in most cases. However, I’m starting to notice that memory usage is spiking - actually, I’ve hit my memory limit… not good! Naturally, the first thing that comes to mind is... DirectQuery! However, keep in mind the limitations - this can also be the slowest storage mode of all. So, Mixed mode to the rescue! We can combine Import and DirectQuery. It sounds so simple when you read about it elsewhere. For example, set up a DirectQuery connection to the central fact table (numerical data), which is usually the largest table, and leave all the dimension tables (descriptive data) in Import mode. That way, memory usage is reduced. Sure, that’s true -you’ll end up with a solution that’s less memory-hungry. But, if your model was big enough to cause memory issues in the first place, trust me, switching to DirectQuery for the largest table won’t give you the best experience. The point I'm making here, without diving too deep (that’s a separate blog), is to explore two things: aggregation tables and dual mode when using Mixed mode (Import and DirectQuery). I’ve used Mixed mode for multiple clients and seen great results.
Now, it’s time to talk about one of my absolute FAVORITE features ever introduced in Power BI,"DirectQuery for Power BI Semantic Models and Azure Analysis Services". Love the feature, hate the name. Why is it relevant here? Well, it allows us to use LiveConnection with Import. How great is that? Let me give you a real example from the past. I was part of a team that built an amazing Analysis Services Tabular Model (equivalent to a Power BI Semantic Model), and we were so proud of it.
But then, I noticed some end-users completely ignoring it when creating their reports. 🤔 What were they doing? They were pulling in all the data from the (any) sources, building a Power BI model from scratch, doing all the ingestion, transformations, modelling, and measures themselves - even though the model we had built handled all of that for them. The problem? It was simple. They had a set of CSV files with updated budget values that weren’t in the data warehouse, so it couldn’t be pushed to the model. I find this to be a common issue, to this day! In the past, we couldn’t set up a LiveConnection to the model and Import an additional dataset like an XLSX file. But now, with this feature (despite its terrible name), we can. To finish up here, I need to caution you all, DO NOT use this to create enterprise models that will be used by large audiences for self-service purposes. This should only be used in a self-service capacity, by the individual needing the analysis. You will have performance issues if you use this feature in such a way. Not going to go into the details here - reach out if you want to know more.
DirectLake
At last, we’ve arrived at DirectLake, and I can sense the excitement! It’s time to dive into the newer storage mode. If you’ve read some other blogs beforehand, you might have come across claims that it combines the best aspects of both the Import and DirectQuery storage modes. While there’s a some truth to this, there are also a few misconceptions that we’ll explore further below.
To get started with Direct Lake, your workspace must be hosted in a Fabric capacity. From there, when we create a Fabric Lakehouse or Warehouse, we will automatically receive asemantic model, or we can create our own. If we establish a connection to this semantic model, we can use DirectLake. This storage mode is optimised for handling large volumes of data that can be loaded into memory from delta tables, which store the underlying data in Parquet files within OneLake.
Why are we hearing it's the best of both worlds? Well, with DirectLake, we aren't loading large amounts of data into memory (which saves on resources) and saving a copy as we do with Import, yet we still achieve the "same" speed. In fact, Power BI can be seen as reading the data directly from the delta tables, therefore underlying Parquet files. Additionally, we aren't sending multiple queries to a relational database as we would with DirectQuery, which often leads to slow performance. Instead, with the improvements Microsoft made to the underlying engine, the semantic model delivers "higher-performance" queries.
Let's check out a few new terms that are important to truly understand DirectLake.
Reframing
We start with reframing, which is equivalent to refreshing our data, a concept most of us should be familiar with. For example, if the underlying source, a Fabric Lakehouse, has additional rows added, we don’t require a scheduled refresh on our semantic model as we would in import mode. Instead, we utilise what is known as a framing operation. The default behaviour is Power BI will detect changes to the data in OneLake and automatically update the metadata of the DirectLake tables included in the semantic model. When users run a report, the latest data from the Delta tables will be retrieved and displayed. From this, we should clearly be able to see the difference between your standard scheduled refresh with Import mode and reframing with DirectLake mode. However, this automatic update may not align with your specific needs - so, it can bedisabled and aligned to your ETL process. If you go to the settings of your semantic model (as we would with Import) we will find the option "Keep your Direct Lake data up to date".
So, DirectLake does not create a copy of the data within the semantic model. Instead, it reads the data directly from the Delta tables in OneLake. This process is known as reframing, where the semantic model checks the metadata for any changes in the Delta tables and updates its references to the latest Parquet files stored in OneLake.
Paging
As we are discussing DirectLake, we must mention what is known as paging. Now, as an early user of Power BI, getting used to some of these terms took some time. However, both reframing and paging are what make DirectLake such a strong storage mode.
When end-users interact with reports and queries are being generated, Power BI will page the data from the underlying delta tables into memory as and when needed. So, the more frequently a set of data is queried, Power BI will keep it in memory. If it's not used as much, it removes it - almost like an eviction process. Paging ensures that only the data required by a query is loaded into memory, which also offers the benefit of reducing the overall memory footprint when compared to Import mode.
An important piece of information, as I understood it, reframing can be seen as the equivalent of refreshing for DirectLake (yet not the same thing). However, it does not actually load the data into memory. Paging is what actually loads the required data into memory when it is needed to run a query. In addition, the semantic model needs to be “reframed” to include the latest data. But here is the thing, when reframing occurs, all data in memory (through paging)is cleared, which isa key to be aware.
Fallback
Last term we must be aware of is Fallback, or DirectQuery Fallback, which, as the name suggests, means converting the DirectLake storage mode to DirectQuery. This happens when the Power BI can't process a query within the constraints of DirectLake mode. In such cases, it automatically falls back to DirectQuery mode, where data is retrieved directly from the SQL Analytics Endpoint of the Lakehouse or Warehouse, rather than using DirectLake's in-memory processing - paging. For more details on fallback and to understand the limitations and guardrails, Microsoft has this well documented here.
Also, if you want to see a visual diagram of how DirectLake works, I believe the Microsoft documentation here has a great 10-step diagram.
DirectLake Summary
To finish up, when I started to discuss DirectLake above, I mentioned that there are a few misconceptions about DirectLake being the best of both words of Import and DirectQuery. So, here is the thing, I'll be honest, when I first saw this released (a while back), I thought it's:
Why am I saying this now? I don't want to mislead anyone, there are a lot of misconceptions out there and more so, I am still exploring this myself. So, be sure to check out this link here by Marco Russo and Kurt Buhler from SQLBI. When something comes from them, it's time to listen. The point here though, Import and DirectQuery still have their place in Power BI - don't just dismiss them.
Conclusion
In conclusion, understanding the various storage modes in Power BI, whether Import, DirectQuery, LiveConnection, Mixed, or DirectLake, can significantly impact the performance and scalability of your solutions. Each mode has its unique benefits and limitations, and selecting the right one for your needs is important.
If you have any questions about choosing the appropriate storage mode or need help structuring your Power BI architecture, feel free to reach out. We've helped countless companies navigate these decisions and optimise their Power BI implementations for success.


.avif)

